Introduction
In today’s rapidly evolving digital landscape, the number of users gravitating towards online experiences is steadily rising, fueling intense competition across industries. Unlike the traditional business world, success in this dynamic environment hinges on the ability to analyze user behavior on digital platforms and leverage data-driven insights to inform strategic decisions.
However, unlocking the true potential of user behavior data requires a solid foundation of a robust and reliable data infrastructure. High-quality data forms the cornerstone of such a foundation, serving as the fuel for accurate analysis and informed decision-making. Unfortunately, some organizations overlook the critical importance of data quality during infrastructure development, ultimately hindering the effectiveness of their data-driven initiatives.
This highlights the pressing need for end-to-end automation in data quality management. By automating data cleansing, validation, and standardization across the entire data lifecycle, organizations can ensure data integrity, consistency, and accuracy. This not only eliminates manual errors and inconsistencies but also significantly improves the efficiency and efficacy of data analysis. This requires a comprehensive data architecture that encompasses data collection, storage, analysis, and utilization, all underpinned by automated data quality management practices.
What is Data Architecture?
Data architecture forms the foundational framework for any data-driven organization. It is an intricate system built upon scheduled data flows designed to make high-quality data readily available to individuals and teams working with data, such as data scientists and product managers. This ensures that all subsystems within the organization operate with consistent, reliable, and valuable data. A general data architecture can be summarized with the following core steps:
- Fetching raw data from a variety of sources like backend logs, physical sensors, third-party marketing tools, etc.
- Automated or manual data quality check as per the business requirements.
- Storing raw data on cloud-based databases or on-premises database systems.
- Analyzing and processing raw data using some big data tools or frameworks according to project scope for artificial intelligence or reporting systems.
- Scheduling all the steps above according to a specific time range for building scalable and sustainable data architecture.
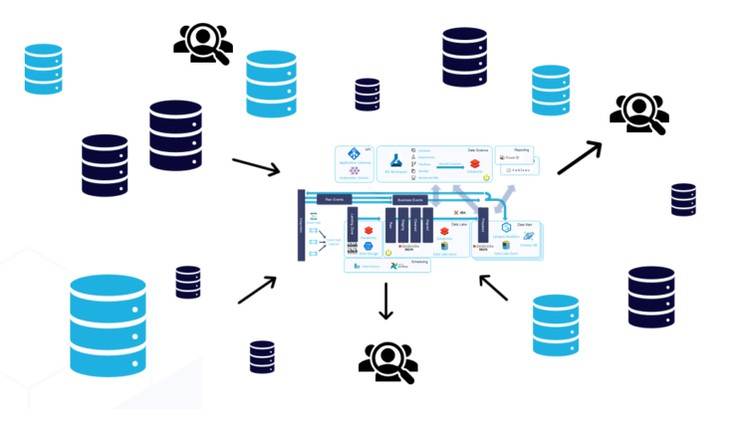
Source
Why is Data Architecture Important?
As the volume and variety of data generated by businesses explode, manual data tracking becomes increasingly impractical and prone to errors, jeopardizing data quality. This can lead to flawed data-driven decisions that ultimately impact the company’s financial performance. Implementing end-to-end automated systems within the data architecture effectively addresses this challenge.
By enabling real-time monitoring of data quality, automated systems empower organizations to swiftly identify and address any anomalies that could compromise the data’s integrity. This proactive approach ensures that business decisions are fueled by reliable and accurate insights, minimizing the risk of losses.
Furthermore, a well-defined data architecture paves the way for seamless and rapid execution of AI and reporting projects. By streamlining data access, integration, and analysis, automated systems accelerate the time to insights, allowing organizations to make informed decisions faster and adapt to evolving market conditions with greater agility.
Role of Data Quality in Modern Data Architecture
Building a robust data architecture is crucial for businesses seeking to leverage artificial intelligence or business intelligence initiatives. However, the success of any such architecture hinges on data quality. Acting on poor-quality data can lead to disastrous consequences.
Imagine pouring advertising dollars into social media campaigns for your newly launched mobile game, relying on data-driven insights to optimize your spending. If the data guiding these decisions is flawed, you could be throwing money down the drain, jeopardizing the success of your game, and incurring significant financial losses.
7 Data Quality Criteria You Can’t Afford to Ignore
Ignoring data quality can lead to misleading insights and disappointing results. To avoid these pitfalls, ensure your data adheres to these crucial criteria:
Accuracy
You can feed your data system from many sources and obtain different values for the same metrics. It is extremely important to determine your main data source for your business goals and take action accordingly. For example, you start collecting marketing metrics with an API integration to track the growth of your app. However, you notice that your admin panel and the integration outputs do not match. In order to make the right decision, you should choose your main data source.
Completeness
Data flowing into systems often originates from diverse sources, encompassing various countries and age groups. When making decisions based on this data for a specific group, relying solely on statistical analysis can be insufficient. Biases within the data can lead to misleading conclusions and ultimately, poor decision-making.
Consistency
As previously mentioned, multiple data sources can feed into your projects, particularly when dealing with legacy systems built on less optimal architectures. When redeveloping such systems, comparing the outputs of both versions becomes crucial. Analyzing discrepancies and identifying the most reliable data source not only ensures accurate decision-making for the current project but also enhances your organization’s knowledge base.
Validity
One of the most common problems for technology teams is the validity of data. The data produced needs to be in the format expected by the business logic, and the majority of its values must fall within a reasonable range. This ensures that data analysis and decision-making are based on accurate and reliable information.
Timeliness
In today’s digital landscape, where users expect 24/7 access and real-time updates, your product must deliver. For example, when offering login and signup services on your web platform, seamless and rapid authentication code delivery is crucial. This is where real-time data processing architectures come into play.
Uniqueness
For reliable data analysis and accurate business assessment, data within systems must be unique and free from duplicate records. Duplicates can skew results and lead to misinterpretations, hindering effective decision-making. By prioritizing data uniqueness, organizations can rely on accurate and reliable insights to make informed decisions, optimize product development, and achieve sustainable business growth.
Relevance
In the chaotic world of real-world data, raw information often arrives messy and “dirty.” Before leveraging this data for valuable analytics, it requires meticulous cleaning through automated pipelines. A crucial stage of this process involves identifying and eliminating anomalous and null values that can distort insights. By implementing business rules, organizations can effectively remove such anomalies, ensuring data integrity and reliability. Additionally, delving into the root causes and sources of these anomalies helps prevent their recurrence and future data contamination.
Conclusion
In the age of data-driven decision-making, ensuring high-quality data becomes paramount. By implementing automated data pipelines and adhering to the key quality criteria discussed throughout this article, you empower your organization to unlock the true potential of its data.
Remember, high-quality data is not merely a technical requirement; it is the foundation for informed decision-making, optimized operations, and ultimately, sustainable business success. Use the insights gained from this article to prioritize data quality and leverage its transformative power to drive your organization toward its goals.